
Planning a semantic model for your product or project
Having the right requirements is essential to design, build, and deliver data for a BI solutions that provide business value. If you design the wrong thing for the wrong problem (or don’t identify the problem at all), your solution is destined for failure… even if it’s using all the latest features or technology, and following all the best practices. But how can you approach requirements gathering for semantic models? What considerations should you keep in mind, and what tools or methods can help?
In this series, we provide tips for how to effectively build a semantic model. In the previous article, we defined what a semantic model is, what a good one looks like, and the typical steps to build a semantic model.
In this article, we describe key considerations for collecting requirements to design and build semantic models. We’ll also describe how you can use Tabular Editor to create model wireframes, and how you can use those wireframes in prototypes or later to accelerate your semantic model development.
NOTE
We recommend that you also read the official guidance from Microsoft on this topic. Articles from the Power BI and Fabric guidance documentation discuss these topics at length:
• BI solution planning (Microsoft): How to plan solutions that support your data and BI strategy. This article describes frameworks to gather business and technical requirements by using a design-thinking approach.
• Gather requirements (Microsoft): Key considerations for collecting Power BI project requirements.
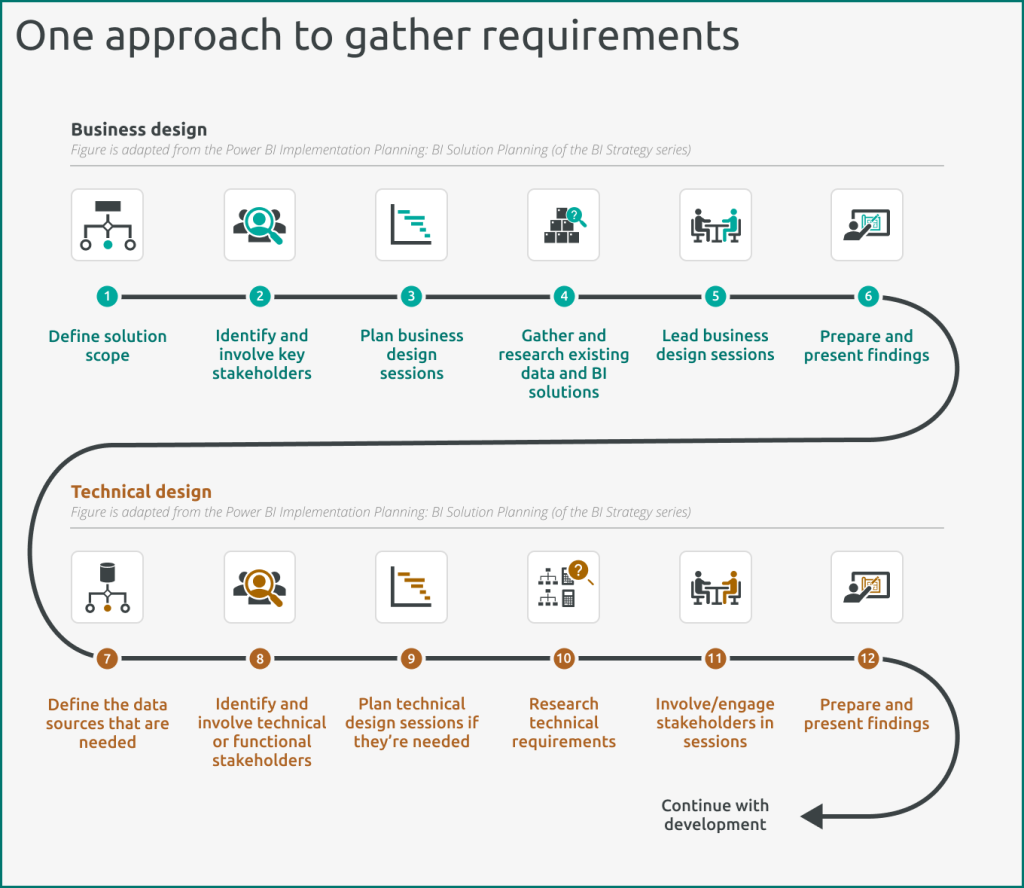
Figure 1: Business design and technical design frameworks to gather requirements (figure adapted from Microsoft’s BI Strategy guidance).
There are also other articles written by the author on this topic which you may find helpful:
• Solve the right problems (Data Goblins): The importance of defining and understanding the problems your solutions should address. This article also emphasizes why BI professionals should be careful not to over-focus on technical problems.
• We need this report in Power BI (Data Goblins): How to engage with business users for successful requirements gathering. This article also describes the pitfalls of lift and shift or requirements documents approaches.
The requirements gathering process
Generally, before you start building a semantic model, you should commence BI solution planning (Microsoft article – Power BI Implementation Planning). The first steps of solution planning is to gather the right requirements. This is an essential step to ensure you design and implement the right model that addresses the right business problems for the right audience. The objective of the requirements gathering process is to ensure that you sufficiently define and understand the right business problems or questions that the semantic model should address:
- Prepare for requirements gathering: Conduct practical planning to gather the people and resources needed for the requirements gathering process.
- Gather business requirements: Define the model scope and gather existing data and BI solutions with that same scope, if available. Then, engage stakeholders in interactive workshops to understand the business problem. Collaboratively describe how this problem will be addressed, i.e. with report mock-ups, user flows, or a simple written proposal.
- Gather technical requirements: Translate the business requirements identified in Step 2 to technical specifications. This is typically the step when you design a semantic model, based on an understanding of the desired end-product for users.
- Plan for deployment: Conduct practical planning to gather the resources needed to start development.
During the requirements gathering process, you should ensure that you’re answering key questions about your semantic model. The answers to these questions determine the approach you’ll take in your model design.
Answer key questions
Some important questions you should answer about your semantic model are described in the following sections. These are examples and don’t necessarily represent an exhaustive list that covers all scenarios.
Questions about how the model will be used

- How many models do you need to make?
Do you need one or more models? Does the scope overlap with existing models used by the business today, or is there a requirement for multiple models to “talk” to one another?- Deciding between one larger model or multiple smaller models involves many factors. Generally, you want to favor scenarios where models are focused on specific business questions/problems, rather than becoming an amalgamation of “all the data that the business could need”.
- Cross-functional reporting can be a complex requirement, and it’s important to define early how you’ll address it (i.e. cross-report drill-through, composite models, other…)
- Will the model serve central reports or will self-service users also query it?
Will the model serve only central reports, or will content consumers with build permissions be able to connect to and query the semantic model?- Self-service models require additional effort to organize and document the model, such as adding display folders and object descriptions.
- Self-service models may require additional effort to ensure DAX is flexible and performant for the possible queries users can generate.
- Self-service users may require special mentoring/training and change management to understand how to use the model (i.e. instead of trying to take large data dumps in Analyze in Excel of all data at the lowest detail level).
- Which downstream workloads and Fabric data items will use this model?
Will the model be used only by Power BI reporting items (like reports or paginated reports) or will it also be used by other Fabric workloads (like with notebooks or reflex)?- You can organize models to make them easier to find and use in these workloads, but some items (like composite models) have a myriad of special considerations / limitations you should know up-front before implementing and using them.
- Special governance considerations may apply for some downstream workloads (i.e. to ensure data is not duplicated in redundant, hat-on-a-hat reporting).
- Which client tools (like Power BI Desktop or Excel) will connect to and use the model?
Will the model be used from Power BI Desktop only, or other tools like Excel (Analyze in Excel or live connected tables) or Tableau Desktop?- Some features (like field parameters and dynamic format strings for measures) won’t work in all client tools, because they rely on properties intended for Power BI Desktop.
- Some client tools may let users view hidden objects (like Power BI Desktop) meaning you have to take special care to not expose irrelevant or sensitive objects.
- What niche features (like translations or perspectives) may you need?
Do you need to implement different cultures for translating model objects? Do report users expect to use personalize visuals or select perspectives when making composite models?- Creating and maintaining translations or perspectives can be a significant additional effort (i.e. they cost you more time).
- What will people actually do with the data once they have it?
Is it expected that users will export data (99.9% of the time… yes)? If so, what will they do with the data once it’s exported? What kinds of decisions do they make or actions do they take based on the reports they use or the queries they make?- Understanding this helps inform your semantic model design so that you can make decisions that help support user’s objectives while mitigating risks.
Questions about the underlying data

- Are there special security or compliance considerations you should take into account?
Do you need to follow special rules or regulations to comply with confidential information, like for data security (row-level or object-level security) or data loss prevention (like sensitivity labels or DLP policies).- Data security has a significant impact on the design and implementation of your model.
- Sensitivity labels restrict certain features, like Fabric Git integration, and have various considerations and limitations, such as downstream label inheritance.
- What are the data sources that you need to connect to and use?
What data sources will be used? Do you need an on-premises data gateway or VNet gateway? What storage mode will be used for these data sources?- Some data sources may require special attention for connectors, gateways, security, performance, or storage mode.
- There are various pros and cons to consider for each storage mode (Import, DirectQuery, and Direct Lake) that go beyond the scope of this article.
- Are there specific naming conventions that you should adhere to?
Are there specific or atypical naming conventions you should conform to? If none exist, how will you name fields consistently so it’s convenient for people to find what they need (and know what it is)?- Fields in the data source may have different names than what they’re called by the business.
- Existing tools and reports may already use naming conventions that users are familiar with.
- What data freshness do users need?
Does the business need “Real-Time” data (do they really need it)? If not, what’s the frequency with which the model should be refreshed? What is the cadence of upstream data updates?- Different requirements for data freshness can motivate key decisions, i.e. about storage mode.
- Import models may require different kinds of refresh policies (incremental refresh).
- Are there transformations needed in Power Query (or further upstream)? Which?
Will the data be “business-ready” with all transformations upstream? Will you need to perform Power Query transformations and–if so–what are the extent of these transformations?- You may not have access to tools or systems upstream to transform data.
- Power Query transformations require additional effort to ensure performant model refresh.
Questions about the model lifecycle

- Who will support the model after it’s deployed to production?
Will you support it once it’s deployed to production (used by the business)? If not, then who?- Support persons will need to understand the model, and should be involved early during its development.
- Early identification and involvement of support persons can reduce the time of handover and reduce confusion or disruption after production deployment
- Will you collaborate during development of the model?
Will you work with others on the same model, thus requiring more mature and robust processes? Will someone else make downstream items or curate the upstream database?- Collaboration often requires source control, for example by using Fabric Git integration (with .pbip files) or Azure Pipelines (with model metadata files).
- Coordinating effectively with teams and individuals working upstream / downstream of the semantic model is critical to ensuring productivity and success.
- How will you manage reporting objects?
Do you need reporting objects to support specific Power BI visual functionalities?- Reporting objects should be organized away from the rest of the model and ideally hidden (for example, in their own measure table) since they’re created for a single, specific context, and not useful for general scenarios.
- Where and how will you document the model?
Will you document the model in a wiki, a word doc, or some other way? Do you intend to comment Power Query (M) code, DAX code, or add object descriptions? Is the time to do this properly factored into your timelines?- Proper documentation takes time and is rarely foreseen during project planning.
- Deciding a lean, sustainable way to document the model, early, can save a lot of headaches later; particularly when integrating with planning processes (i.e. in DevOps).
- Do you expect future changes or additions to the model, and how should they be handled?
Will the scope of the model change over time, or will its adoption grow to a broader audience? How will these changes be handled?- Planning for and anticipating change ensures that the model is scalable and flexible.
- Deciding a lean, sustainable way to document the model, early, can save a lot of headaches later; particularly when integrating with planning processes (i.e. in DevOps).
Design the model: wireframing in Tabular Editor
By now you should have a sufficient understanding of the business questions and problems that this semantic model should address. You also have a sufficient understanding of the technical requirements for your semantic model, by answering questions like those described in the previous sections. Next, you’ll have to design your model.
When designing a model, it can be helpful to create a wireframe. A wireframe is a model without any data; essentially, you’re just creating the diagram abstraction of the model… the design.
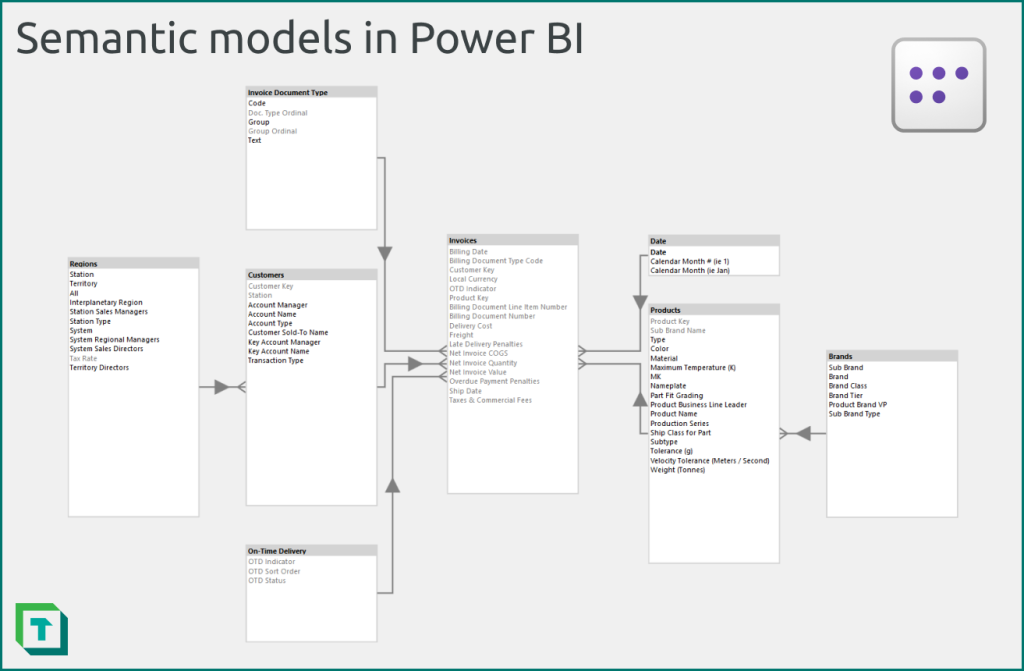
Because Tabular Editor works in disconnected mode (i.e. you don’t need data or a persistent active connection to a database), you can create a model wireframe by using model metadata. This has several benefits:
- Validate assumptions: Test assumptions about business or technical requirements before development, which can save you time, later.
- Better estimates: Understand better the effort and time required to develop the model, particularly if you already organize the wireframe.
- Create a North star: Represent technical requirements with an actual semantic model design, so it’s clear what the envisioned result is for everyone.
- From wireframe to prototype to semantic model: Because you’re working in Tabular Editor, your wireframe can be easily adapted to a functional model. For example, you can add partitions with sample data from static tables to create a prototype. Later, when you’re ready to start development, you can also just connect to your data source(s) and leverage everything you’ve done in your wireframe.
Creating a wireframe in Tabular Editor is straightforward. You just create a new model and start adding objects without any data source.
How to create a semantic model wireframe in Tabular Editor
To create a wireframe model in Tabular Editor, follow the below steps:
- In Tabular Editor, create a new model and save the metadata.
- Create table objects, or copy them from existing, similar models.
- Add shared expressions you might need (i.e. for connection string parameters). Don’t forget to set the “Type” to “M”.
- Create columns you expect to have in each table. Ensure that you specify the properties:
- Data type: The data type of the column (i.e. Integer).
- Sort by Column: If you expect atypical sorting (i.e. Weekday name sorted by Weekday #).
- Source Column: The name of the column in the source (i.e. typically the same as the column name).
- Create a model diagram and drag and drop fields to create relationships.
- Create calculated tables for specific cases like date tables or field parameters.
- Create calculation groups for specific cases like time intelligence or measure replacement.
- Create DAX measures to explicitly aggregate columns, or for fields / KPIs identified as strategically important in the business requirements.
- Create the anticipated roles for data security, as well as the table and object permissions, if they’re already known.
- You can also set key properties (like Refresh Policy) or organize the model (into Display Folders or Table Groups).
- Save the model and diagram, taking a screenshot of the diagram as a visual representation of the wireframe.
You can also later use this wireframe during development:
- Prototype: To convert the wireframe to a prototype, you just have to enter the appropriate Power Query (M) syntax to specify mock data in the table partition(s). These can be simple static tables of 5-25 rows, just to demonstrate functionality and validate DAX.
- Development model: To convert the wireframe to a functional model, you just have to replace the partitions with ones that specify the connection to your data source. If you’re using an explicit data source object (i.e. for AAS / SSAS), you have to add that object, as well. Ensure that your table schema matches the table in the database.
In conclusion
Gathering the right requirements is critical for any data and BI project, to ensure that you arrive at the desired result. When building a semantic model, this involves clearly defining the business problem/question being addressed and translating the business requirements you gathered into technical requirements effectively.
A good way to do this is by answering a set of key questions about your model, then creating a model wireframe to represent your anticipated design. Tabular Editor can be a good tool to create a model wireframe, since you can also benefit from this work later if you need a prototype or proof-of-concept. Furthermore, you can also convert this wireframe to a fully functional model in a few simple steps.

Pingback: DAX basics in a semantic model – Tabular Editor Blog
Pingback: Validate semantic model relationships – Tabular Editor Blog
Pingback: Prepare your data for a semantic model – Tabular Editor Blog