
Test that your relationships are set up and work as you expect in your semantic model.
In this series, we provide tips for how to effectively build a semantic model. In the previous article, we described how you create relationships in semantic model. Relationships are one of the most important parts of a semantic model, as they’re the foundation of your business logic.
In this article, we describe how you can validate the relationships in your semantic model to ensure that they’re set up correctly. Validating your relationships helps ensure that you don’t have unexpected results or performance issues in your reports.
- Semantic models in simple terms: what is a semantic model?
- Gather requirements for a semantic model.
- Prepare your data for a semantic model.
- Connect to and transform data for a semantic model.
- Create semantic model relationships.
- Validate semantic model relationships (this article).
How to validate relationships
Once you create a relationship, you should test that it works as you expect. This is particularly important when you use atypical properties in the relationship or if you are using the relationship in uncommon scenarios. An example of an uncommon scenario might be inactive relationships with a role-playing dimension, or relationships with a many-to-many cardinality. Once you create your relationships and process your model, you’re ready to validate these new relationships.
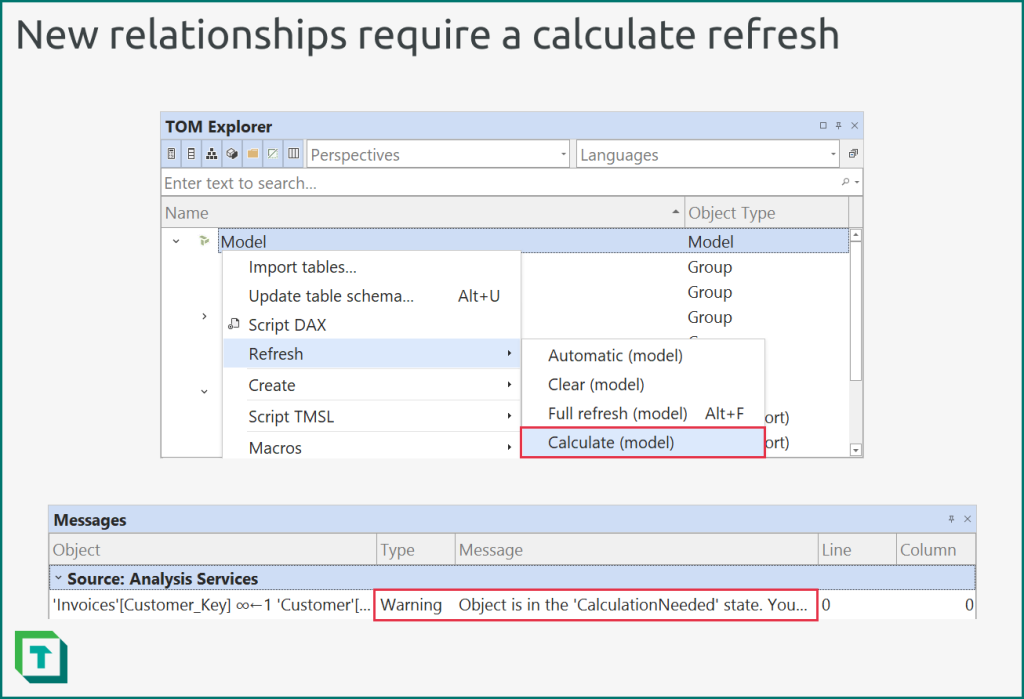
This calculate refresh occurs automatically when you add a relationship to a local model by using Tabular Editor or Power BI Desktop.
The following diagram depicts examples of issues you encounter with relationships.
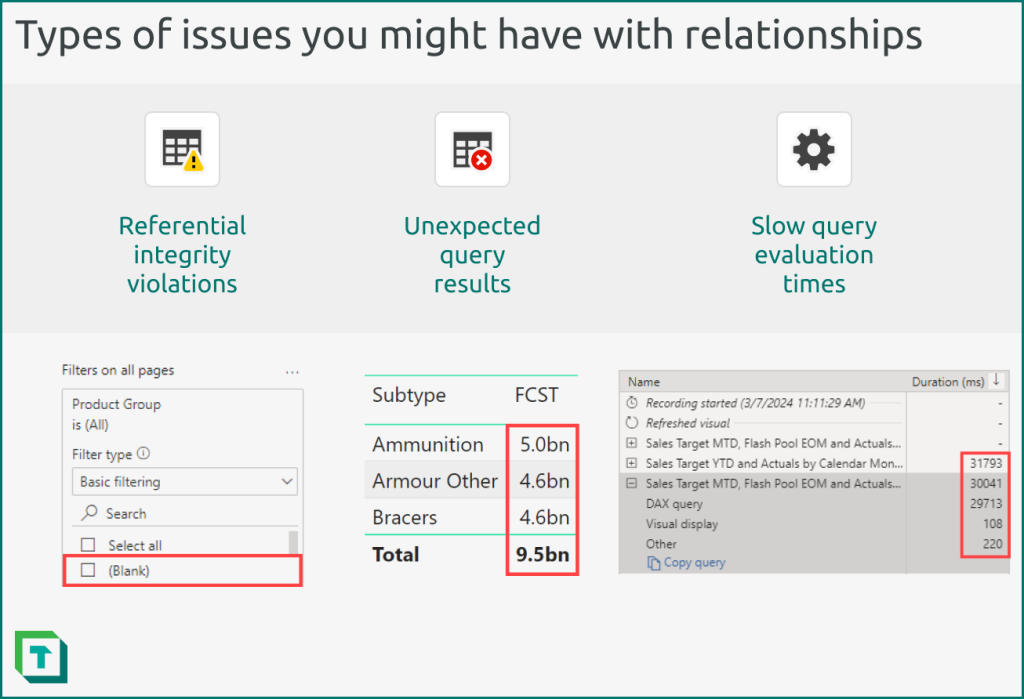
When you validate a relationship, you should look for the following:
- Referential integrity (RI) violations: Missing values on the “from” side (typically the dimension table) which are present on the “to” side (typically the fact table). The most common issue caused by RI violations in a semantic model is that (Blank) values will appear in Power BI reports, which confuse users and reflect poor data quality. RI violations are also commonly thought to cause performance issues in a semantic model, although there’s no concrete, consistent evidence of this; it depends upon your data and your semantic model.
- Unexpected query results: Relationships that aren’t properly configured might produce results that differ from your expected baselines. This is more likely when you use atypical properties for your relationships. Testing these atypical relationships is particularly important so that you’re sure that these specific relationships don’t negatively impact the perceived quality of your models. To identify these issues, you typically use report visuals or DAX queries.
- Slow query evaluation times: High cardinality relationships can sometimes result in performance issues. You may need to validate these relationships to see if you need to reshape your data or change your model design. To identify these issues, you can use the performance analyser in Power BI Desktop or DAX Studio.
You can validate relationships by using Power BI Desktop, Tabular Editor, or Microsoft Fabric (Semantic Link in Notebooks).
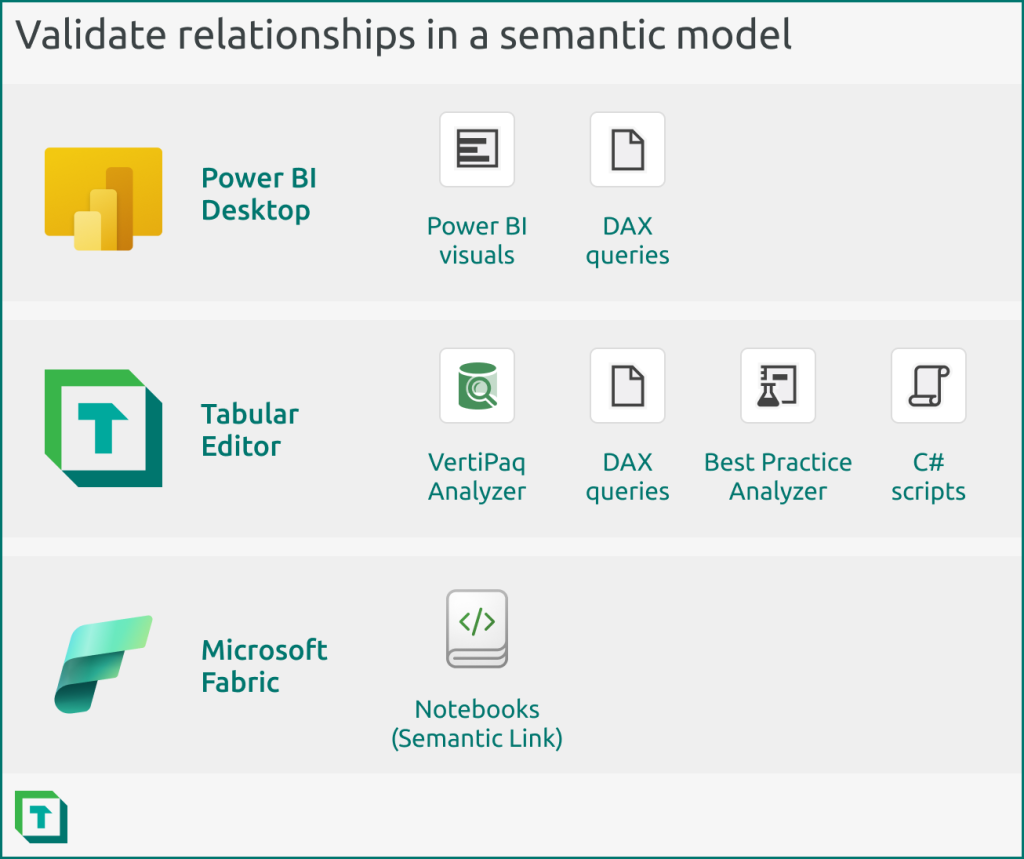
Generally, your choice of tool depends upon your preferred workflow and needs.
- Power BI Desktop: You can validate your relationship by using the visual canvas or DAX queries in Power BI Desktop. You should use Power BI Desktop to validate your relationships if it’s the main tool that you use to build your semantic model.
- Tabular Editor: You can validate your relationship by using the VertiPaq Analyzer or DAX queries in Tabular Editor. You can automate this validation by using certain Best Practice Analyzer rules and C# scripts. You should use Tabular Editor to validate relationships when you are using Tabular Editor as an external tool for Power BI Desktop, or if it’s the main tool you use to build your semantic model. You should also use Tabular Editor to validate your relationships when you need automation, or in more complex scenarios and models.
- Notebooks: You can validate your relationship by using various features of Semantic Link in notebooks in Microsoft Fabric. Semantic link is unique because it has several built-in functions to analyse and visualize relationships. You can also schedule this notebook validation. However, you can’t (currently) write back to your model, so this analysis is read-only and an extra step external to the model development, itself. It also only works if your model is published to a workspace in a Fabric capacity; you can’t analyse local models open in Power BI Desktop, or model metadata files that aren’t uploaded to a Fabric capacity. You should use notebooks to validate relationships when you are comfortable with working in Python and using notebooks, or you’ll be using your semantic model (and its data or logic) for downstream consumption/analysis in notebooks and ML models.
The following sections describe examples of how you can use each of these tools to validate relationships, with particular focus upon identifying and resolving RI violations.
How to identify relationship RI violations
RI violations are straightforward to objectively identify, while unexpected or slow queries require a baseline or context to test. That’s why in this article, we’ll focus on how you can identify RI violations by finding invalid rows and missing keys.
The following diagram depicts an example of RI violation in a one-to-many relationship between a customer dimension table and a sales fact table.

To identify these RI violations, you can take various approaches and use various tools. To reiterate, the choice of tool depends upon your preference and workflow. What’s most important is that you can identify and resolve the RI violations, where possible.

Johnny Winter has an excellent blog discussing this topic in detail over at Greyskull Analytics that we recommend you read: The “Unknown Date” Dilemma.
Validate a relationship by using Power BI Desktop
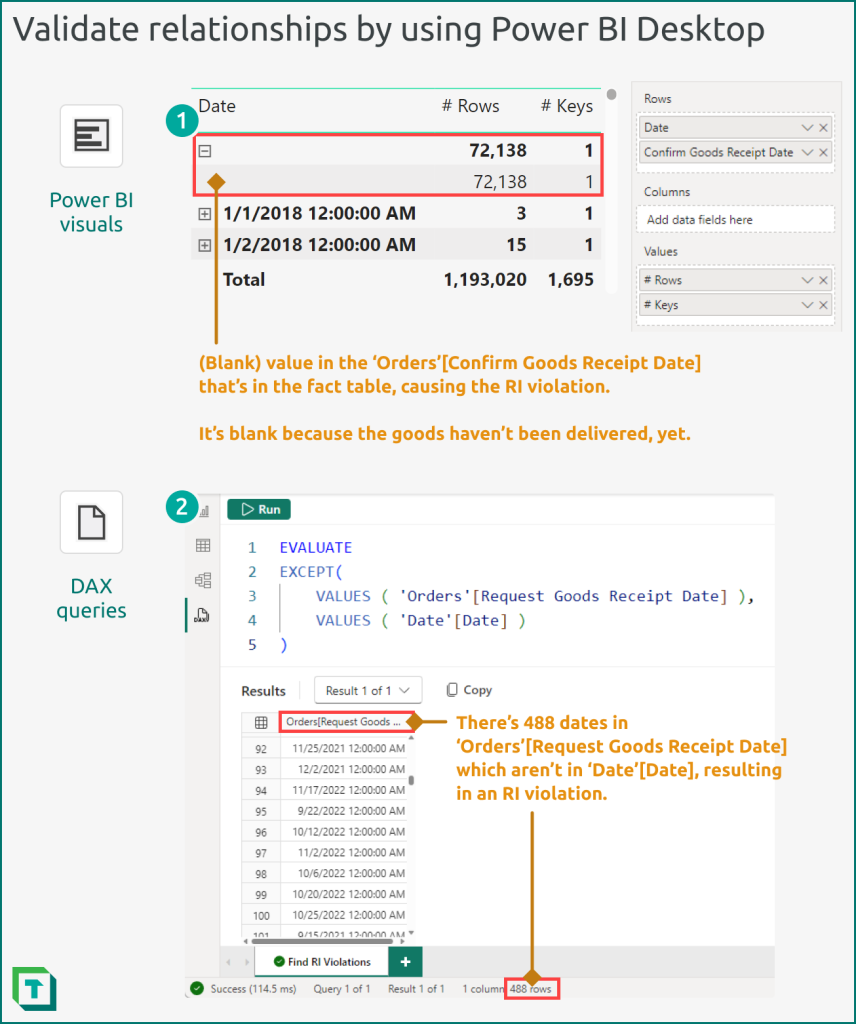
You can use the following approaches to validate relationships in Power BI Desktop.
- Power BI Visuals: The easiest way to do this is to use a matrix visual, creating an arbitrary hierarchy of the primary key (on the “From” side; usually the dimension table) and beneath it the foreign key (on the “To” side; usually the fact table). You then add a measure that counts the values of the foreign key (and also potentially the number of rows in the fact table). The measures help you identify the magnitude impact. Expand the matrix and sort it alphabetically ascending, looking to identify any blank rows in the primary key. The presence of these blanks indicates an RI violation, and the lower level of the matrix will reveal which keys are missing (and how many rows are affected).
- DAX Queries: You can achieve the same result as (1) by using a DAX query. The simplest DAX query uses the EXCEPT function to identify keys that are present in VALUES ( ‘Fact’[Foreign Key] ) but not in VALUES ( ‘Dimension’[Primary Key] ). You can export these results to use in investigation and data cleaning steps with your source data.
Validate a relationship by using Tabular Editor
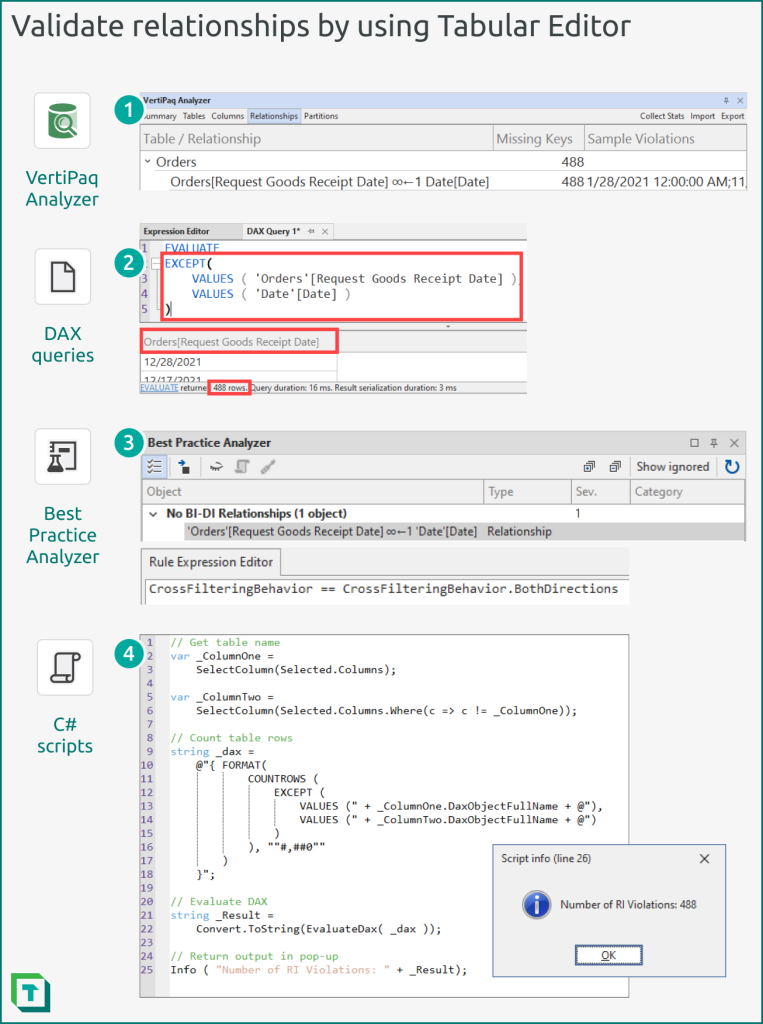
You can validate relationships by using Tabular Editor in four ways:
- VertiPaq Analyzer: The VertiPaq Analyzer is a helpful tool that will identify and raise any RI violations found in your model. It will provide supplemental information about the violating relationships, and also sample values of the keys that are missing. You can change how many samples are shown from the preferences menu of Tabular Editor. The .vpax results can also be saved as documentation, for later reference.
- DAX Queries: You can use DAX queries identically as you would in Power BI Desktop. In Tabular Editor, you can also save these DAX queries to re-use in other models or to automate in C# scripts.
- Best Practice Analyzer (BPA): You can define rules in the BPA which identify potential issues with relationships. Custom rules that you define with C# can perform more complicated steps, though the BPA can’t query the model to identify RI violations. Instead, you can use automated C# scripts to flag RI violations and save them as annotations in your relationships, which the BPA can flag as an issue.
- C# Scripts: C# Scripts can automate the detection of problematic relationships or RI violations. They can execute DAX queries, but also use functions that retrieve VertiPaq statistics or other metadata to inform downstream steps that can immediately correct these issues or flag the relationship for later investigation and validation (once the source data is corrected).
Validate a relationship by using Semantic Link in Fabric Notebooks
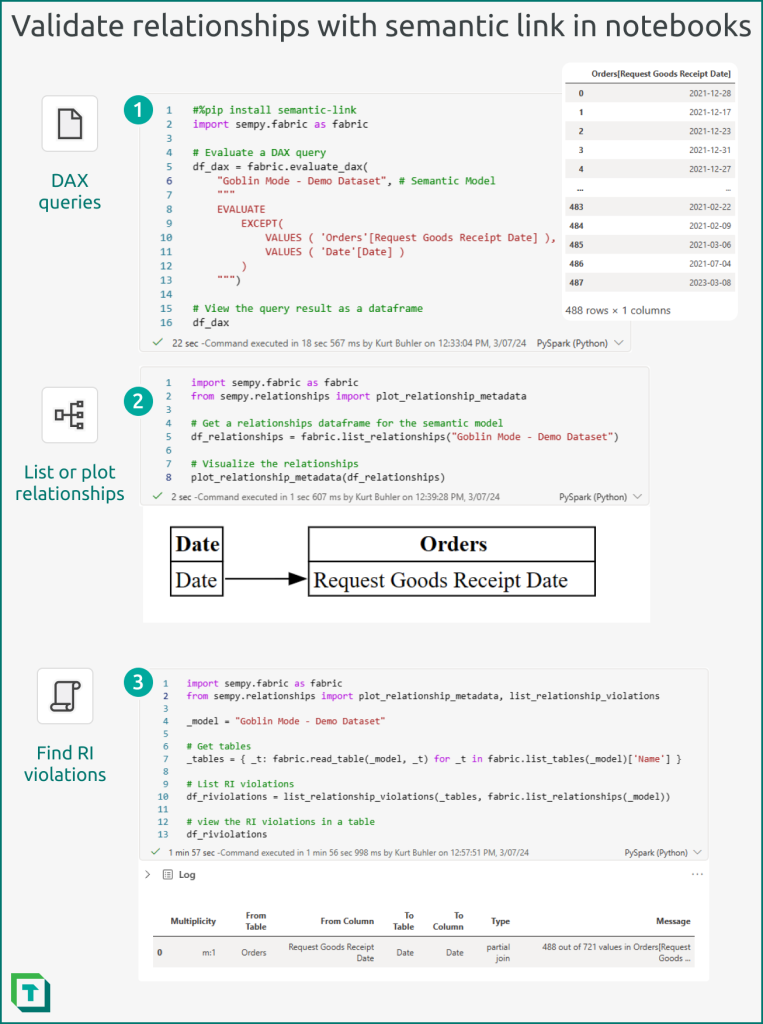
In Fabric Notebooks, you can use Semantic Link to connect to a published semantic model and interact with it programmatically by using Python.
- DAX Queries: You can execute DAX Queries within notebooks, taking a similar approach as you would by using Power BI Desktop or Tabular Editor DAX queries.
- Visualize relationships: You can create a model-like view of specific relationships (from a relationships dataframe obtained by list_relationships) by using the plot_relationship_metadata function.
- sempy.relationships: You can retrieve and validate relationships by using SemPy library. There’s different functions that you can use, depending upon your needs:
- list_relationships: Returns the existing relationships in a relationships DataFrame.
- find_relationships: Attempts to find potential relationships in a relationships DataFrame with better performance than the autodetection of Power BI Desktop. Note that you can’t yet write these discovered potential relationships back to the model from the notebook.
- list_relationship_violations: Returns a DataFrame with a summary of all the RI violations from a relationships dataframe (either of physical relationships in the model found with list_relationships, or potential relationships discovered by find_relationships).
You can scale and schedule notebooks so that they run these validations and analyses over multiple semantic models. This can be helpful to automatically detect data quality issues in deployed models caused by issues with the underlying source data. Conditional logic in scheduled notebooks can also trigger downstream actions or updates in response to invalid relationships, such as modifying a table or triggering another tool to notify a data steward.
In conclusion
It’s essential that you validate relationships both after you create and process them, as well as once you’ve finished developing your DAX and RLS/OLS. Typically, you want to identify common issues like RI violations (missing keys) or more subtle issues in performance or query results. You can test your relationships by using Power BI Desktop, Tabular Editor, and notebooks in Fabric. What’s most important is that you do these tests and ensure that your relationships behave as you expect before you introduce additional logic on top of them in your model.

The thing with referential integrity is that you need to test it after each refresh. But with some measures, you can have it in no time. This article presents a c# script that can help you monitor all your one-to-many relationships, even if they are inactive https://www.esbrina-ba.com/easy-management-of-referential-integrity/
Hi Bernat
Great article! Love the use of C# scripts to automate the development of this kind of audit measures.